Instaluję Scrapy na moim systemie operacyjnym (Ubuntu):
sudo apt-get install python-dev python-pip libxml2-dev libxslt1-dev zlib1g-dev libffi-dev libssl-dev
sudo pip install scrapy
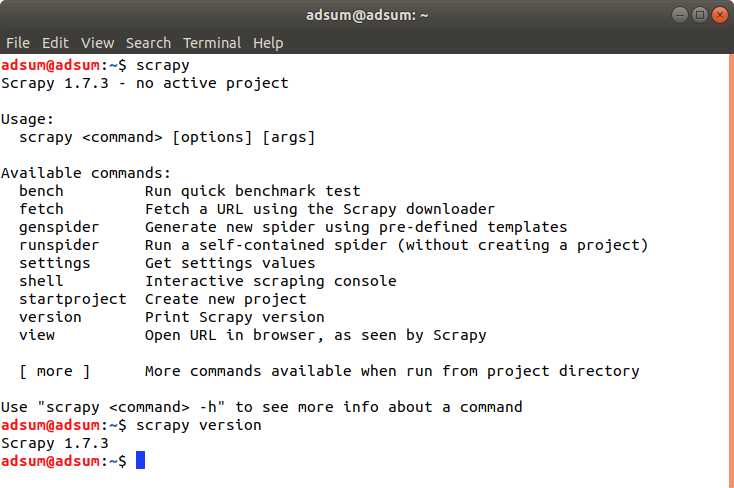
Uruchomiam w terminalu Scrapy:
scrapy
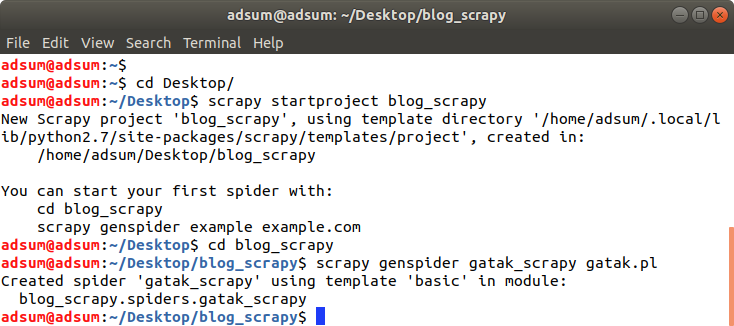
Aby rozpocząć nowy projekt wybieram ścieżkę, a następnie:
scrapy startproject nazwa_projektu
Wchodzę do stworzonego projektu, a następnie:
scrapy genspider nazwa_spidera nazwa_domeny(bez: http://www)
Następnie uruchamiam shell, oraz podaję adres strony. Tutaj będę sprawdzał, czy moje response są poprawne :
scrapy shell
fetch(„http://www.gatak.pl”)
Założenie jest takie, aby pozyskać wszystkie tytuły wraz z kategorią i datą publikacji. Dla przejrzystości ustawię kolejność: kategoria/data/tytuł
Dane, które chcę pozyskać wypisane są pod każdym artykułem na stronie głównej.
Odpalam Inspect strony. W kolejnym kroku należy mieć podstawowe pojęcie na temat HTML. Łatwo można zauważyć, że potrzebne dane zawarte są w <article></article>
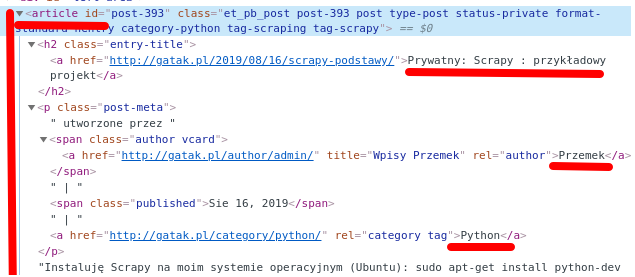
Sprawdzam w shell, co wyświetli mi się, gdy utworzę response dla <article>
Można używać response.css lub response.xpath. Ja użyję xpath. Podstawowa zasada jest taka, że piszemy response.xpath(’//czego_szukamy’). Np. response.xpath(’//h2′).
W niektórych przypadkach(np. wyszukując klasę) używamy składni response.xpath(’//*[@class=”nazwa_klasy”]’)
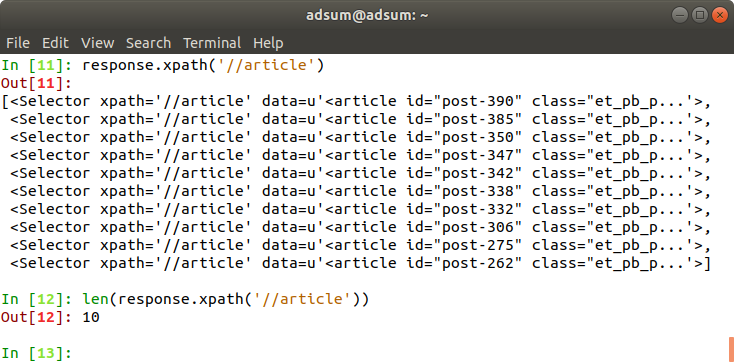
Jak widać, otrzymałem 10 selektorów. Odpowiada to liczbie artykułów. Łączna liczba artykułów na blogu jest większa, natomiast na stronie pierwszej jest ich 10.
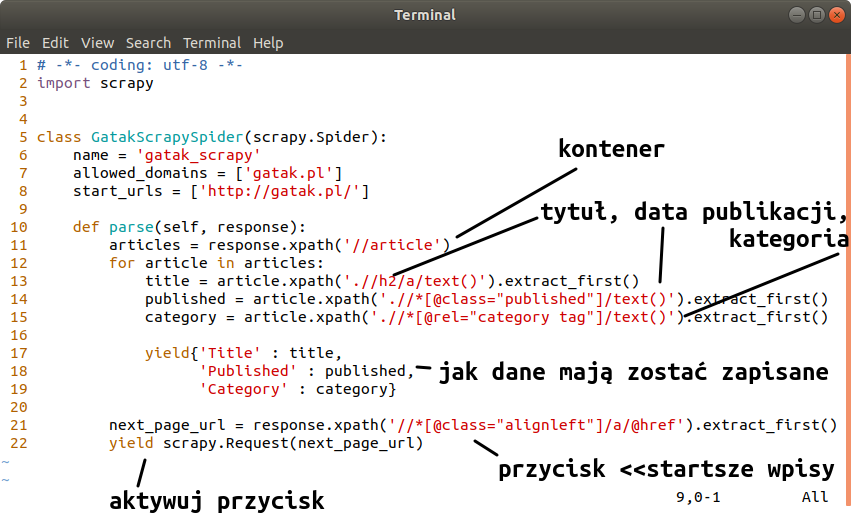
Każdy selektor(artykuł) będzie oddzielnym kontenerem z którego pozyskam potrzebne dane.
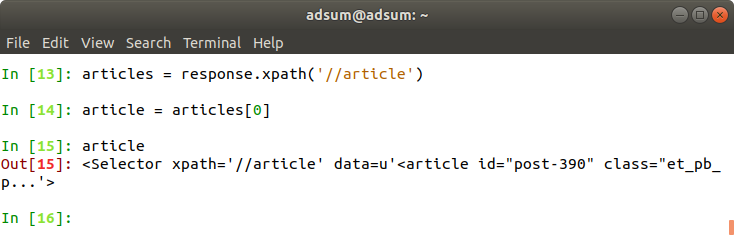
Aby dostać się do pojedynczego artykułu używam articles[0]:
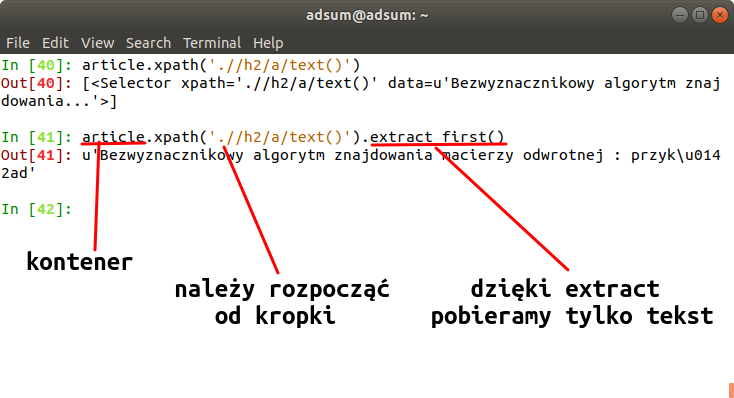
Teraz pozyskam dane dla pojedynczego kontenera(artykułu):
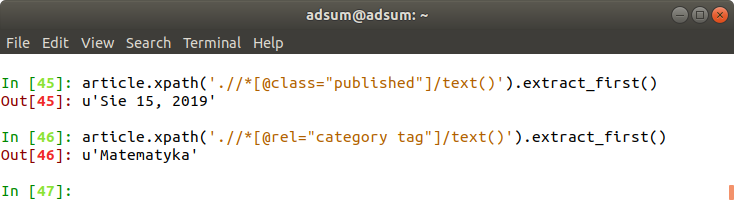
Następnie określam response dla daty publikacji, oraz kategorii:
Kolejnym krokiem jest przejście na kolejne strony bloga. Na stronie służy do tego przycisk <<starsze wpisy. Robię inspekt i postępuję tak jak z poprzednimi przykładami.
Kolejnym krokiem jest stworzenie pająka. Należy wejść do pliku spiders i otworzyć plik py z nazwą naszego projektu i uzupełnić kod o dane, które zostały wcześniej uzyskane:
Aby uruchomić pająka wchodzę w terminalu do folderu z projektem i wpisuję polecenie: scrapy crawl gatak_scrapy -o items.csv
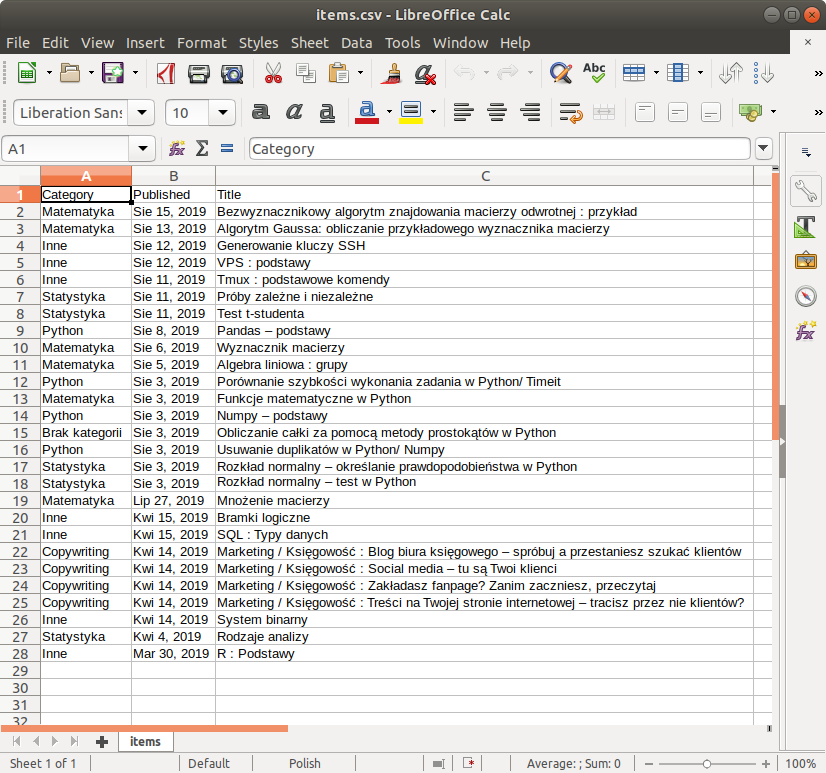
W folderze projektu został utworzony plik items.csv :